2025年11月18日Cloudflare宕机事故解读
-
Cloudflare系统状态公告:www.cloudflarestatus.com
-
Cloudflare博客:blog.cloudflare.com
-
本次事故官方故障报告:blog.cloudflare.com
2025年11月18日,互联网基础设施服务商Cloudflare出现了长达5小时的故障,包括OpenAI、X在内的大量头部互联网服务全面瘫痪。

Cloudflare作为互联网基建服务的核心参与者,其自身的系统稳定性也成为了互联网脆弱性的根源之一。
完整事故回溯
作为全球最大的CDN(内容分发网络)之一,Cloudflare的核心定位是互联网流量的第一道关卡。
能够达到如此市场规模,Cloudflare自然不局限于基础的流量加速功能。防火墙、限流、监控、Debug等功能均已成为其CDN服务的标配。
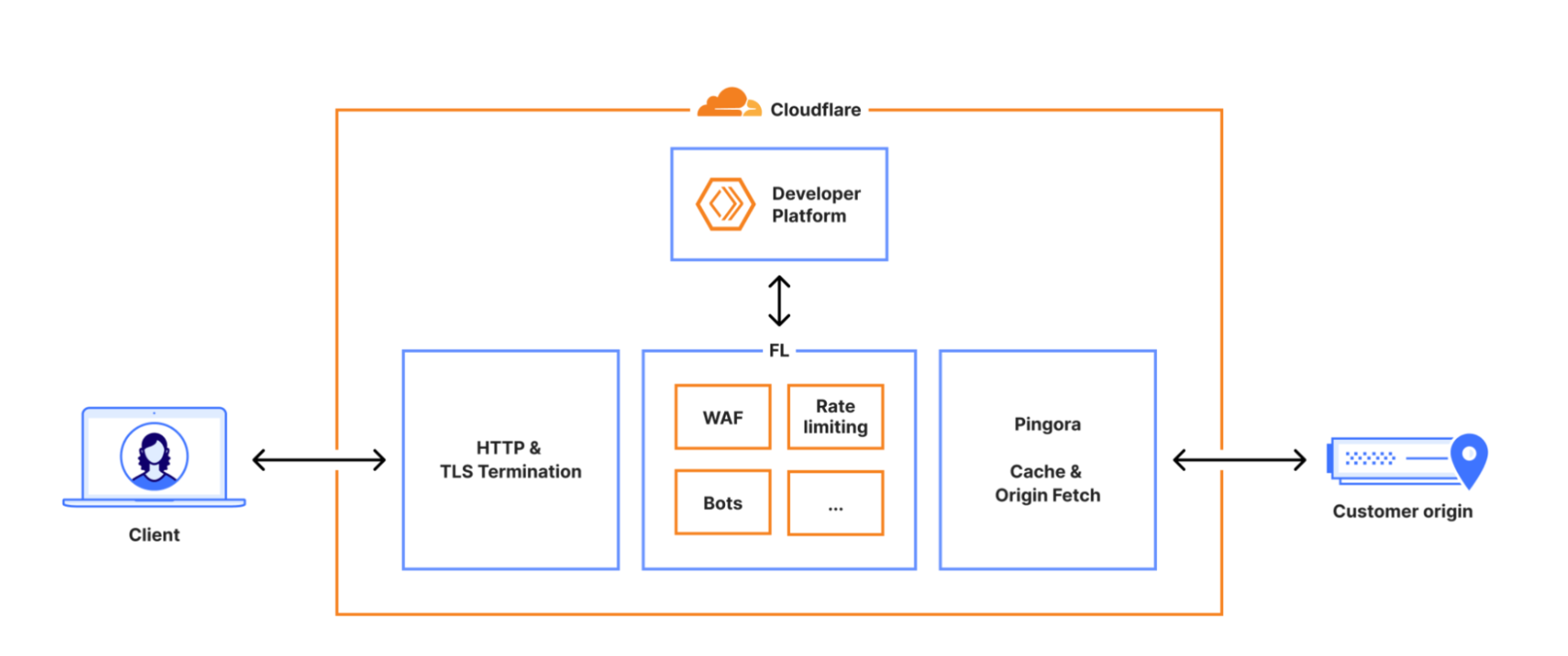
这其中包含一个名为Bot Management(BM,机器人管理) 的核心模块。顾名思义,该模块用于检测HTTP请求是否来自爬虫等机器人程序。其运行机制是每隔几分钟从数据库获取最新的特征数据,以此更新自身的检测模型。
在11:05,Cloudflare工程师对数据库的权限设置进行了更新(X上说罪魁祸首疑似...)。
此次权限更新引发了连锁反应,导致数据库返回的数据出现异常。到了11:28,BM模块按预定周期连接数据库时,获取到了存在问题的数据。由于模块对此类异常数据缺乏防御机制,直接导致整个BM模块崩溃,所有HTTP请求均被报错拦截。
由于数据库补丁采用渐进式发布,当时仍有部分数据分片未更新到存在问题的版本。这就导致BM模块下一次定时更新时,若恰好连接到未受影响的数据库分片,就能获取到正常数据,检测功能便会临时恢复,故障现象也随之消失。
因此从11:30到13:30,请求报错量呈现出“过山车”式的波动——时而激增、时而骤减,甚至短暂完全消失后又再次拉满。这种异常现象使得Cloudflare工程师在前两个小时内,始终将事故判定为黑客组织发起的DDoS攻击。
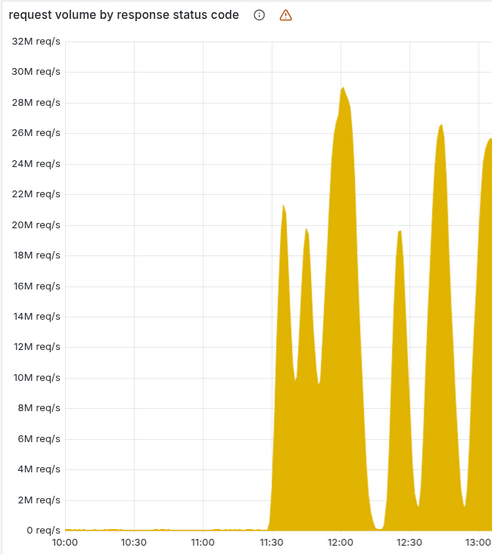
直至13:30,数据库补丁的滚动更新全部完成,所有数据分片均出现异常,报错曲线才变为平稳的直线。
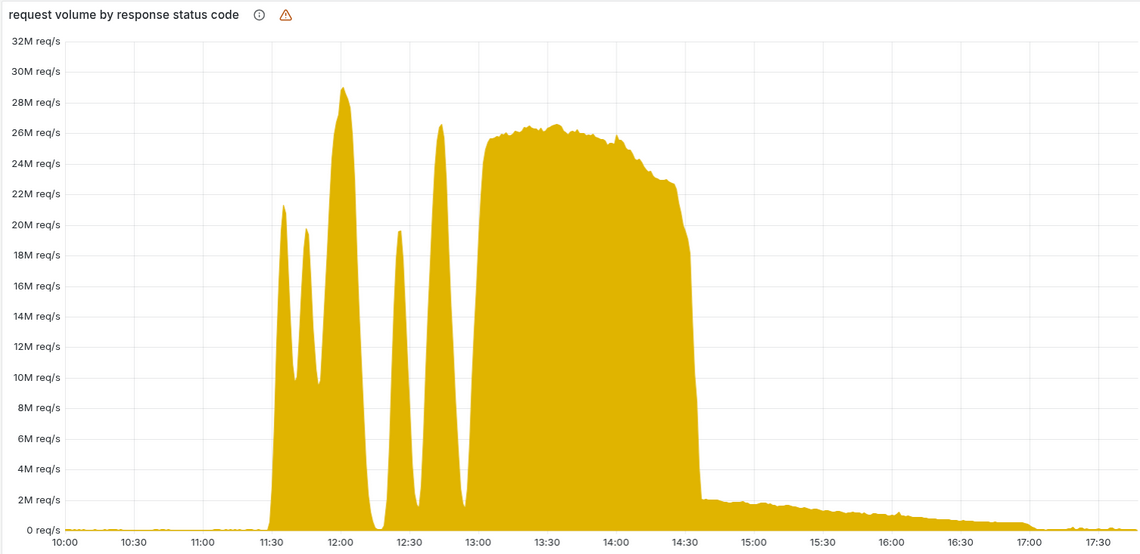
此时工程师们才意识到故障可能源于内部系统,随即快速定位到BM模块及存在问题的数据,并尝试对数据进行回滚。但这一操作并未解决根本问题——不久后BM模块会再次从数据库获取到异常数据。直到14:24,工程师才找到问题根源,暂停了BM模块的定时更新功能,并手动部署了一份正常数据。6分钟后,全球范围内的BM模块同步了正常数据,CDN服务开始逐步恢复。最终在17:06,所有受影响的服务陆续恢复正常,此次故障正式结束。
事故原因:BUG深度解析
六年前,Cloudflare曾因工程师写错一段正则表达式,引发了当时互联网历史上最严重的全球瘫痪事件。或许受此影响,在BM模块的设计中,团队未采用正则表达式过滤HTTP请求,而是选择传统机器学习构建Classifier(分类器)模型。
Classifier模型的准确性取决于特征(feature)的选择。一个HTTP请求可作为特征的显性信息已十分丰富,因此BM模块未写死特征列表,而是从数据库动态获取——这一设计旨在确保所有Classifier能第一时间拿到最新、最全的特征数据。
在数据库中,存储这些特征的表格名为http_request_features,每一列对应一个特征。由于历史遗留问题,BM模块需先通过名为Default的数据库获取该表格的元数据(即各列的名称、类型等信息)。在BM模块的代码中,这一步骤通过一条简单的SQL语句实现:
SELECT name, type
FROM system.columns
WHERE table = 'http_requests_features'
order by name;
获取元数据后,BM模块再通过名为R0的数据库读取表格中的对应数据。这种设计本身存在冗余——既然允许用户读取R0上表格的数据,便无需将元数据存储在另一数据库中。
Cloudflare工程师也意识到了这一问题,因此在11月18日上午11点05分推送了一项更新:为用户添加直接读取R0元数据的权限。理论上,这能让用户在R0上完成所有操作,既提升效率,也增强安全性。
权限改动本身并无问题,症结出在上述SQL代码中——语句仅指定了要查询的表格名称,却未明确所属的数据库。
若使用PostgreSQL等数据库,此类问题不会发生,因为PostgreSQL的数据库之间相互隔离,用户每次连接仅能访问一个数据库及其中的数据。但Cloudflare采用的是ClickHouse数据库,其核心优势是高性能,而高性能的实现需要在部分功能上做出取舍——在读取权限设置上,ClickHouse采用“隐式范围控制”,即用户的查询可见范围由其数据读取权限决定。
因此在权限补丁发布后,用户同时拥有了Default和R0数据库的元数据读取权限,上述SQL语句便会同时返回两个数据库的system.columns数据。
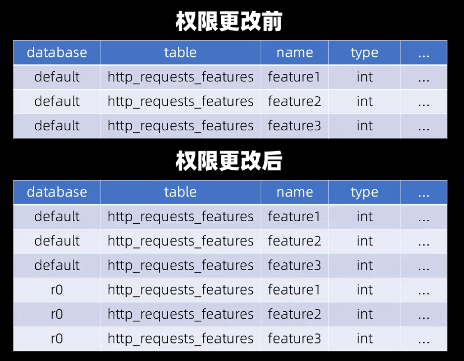
最终返回的是每个列都重复一遍的特征列表,这组错误数据正是事故的导火索。事实上,若在WHERE条件中添加database=default或database=R0,或使用SELECT DISTINCT过滤重复数据,即可避免这一问题。
BUG的下游影响:Rust代码层面
Cloudflare的核心目标之一是“更快、更快、更快”,因此在BM模块代码中采用了PreallocateMemory(预分配内存)的做法——提前为特征列表预留一段内存空间,避免运行时动态检查列表长度并分配内存。预留的空间可容纳200个特征,而正常情况下一个HTTP请求最多仅需一百余个特征。
在将特征列表并入数组的Rust代码中,针对潜在的数组溢出错误,开发人员使用了unwrap方法处理。
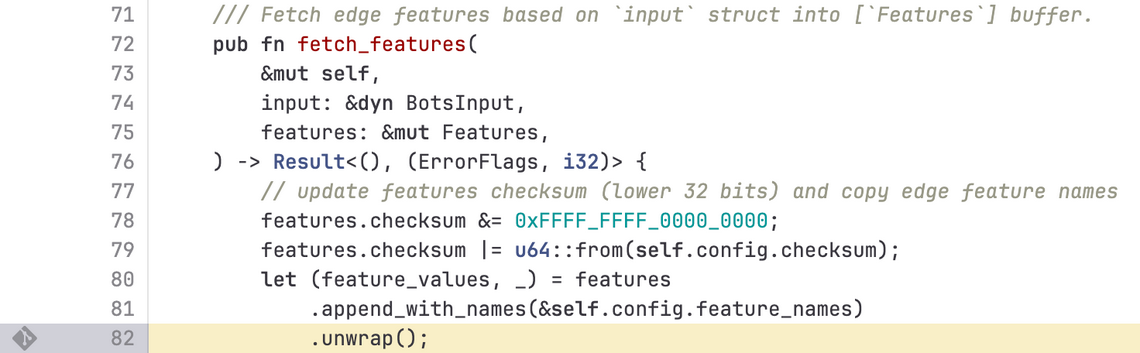
在Rust语言中,unwrap方法一旦遇到错误就会终止整个程序,这直接导致了HTTP请求报错。Rust强制要求开发者处理所有错误,这本身是良好的设计规范,而unwrap本质上是一种简单粗暴的错误处理方式——数据正常则返回结果,数据异常则直接终止程序。
由于Cloudflare近期正处于BM模块引擎的升级阶段,迁移工作尚未完成,系统内部同时运行着两个版本的引擎。新版引擎因使用了上述unwrap代码,导致HTTP请求出错;而仍在使用旧引擎的用户虽未出现报错,但由于Classifier模型获取到异常数据,无法正常打分,只能统一返回0分。在正常逻辑中,0分仅赋予内部系统请求,目的是让BM模块跳过检测直接放行;但在此次BUG影响下,所有外部请求均被默认放行,BM模块形同虚设,工程师甚至难以第一时间发现模块已实质性停摆。
从SQL代码中缺失的查询条件,到应用代码中固定的数组长度,这些低级编程错误本质上是开发者为图便利而走的捷径。而这种“捷径思维”不仅存在于底层代码,在顶层架构设计中也同样存在。